Topic是Kafka的基本组织单位。Kafka的消息是以Topic作为基本单位来组织的,而多个Topic之间又是相互独立的。
形象的说,可以将Kafka当成一个队列集合,每一个Topic相当于一个队列。
每个Topic又分为多个Partition,也就是分区,分别存储了一部分的消息,也起到了负载均衡的作用。
创建Topic的时候,可以指定partition的个数,最终以文件形式存储在磁盘上。
1 | ./kafka-topics.sh --create --partitions 3 --topic test_p_3 --zookeeper localhost:2181 --replication-factor 1 |

每个partition以Topic名称-Partition序号来命名,底下又分为多个Segment,也就是分段。
生产消息的时候,需要指定Topic,而Topic根据Partition路由算法,路由到具体Partition。
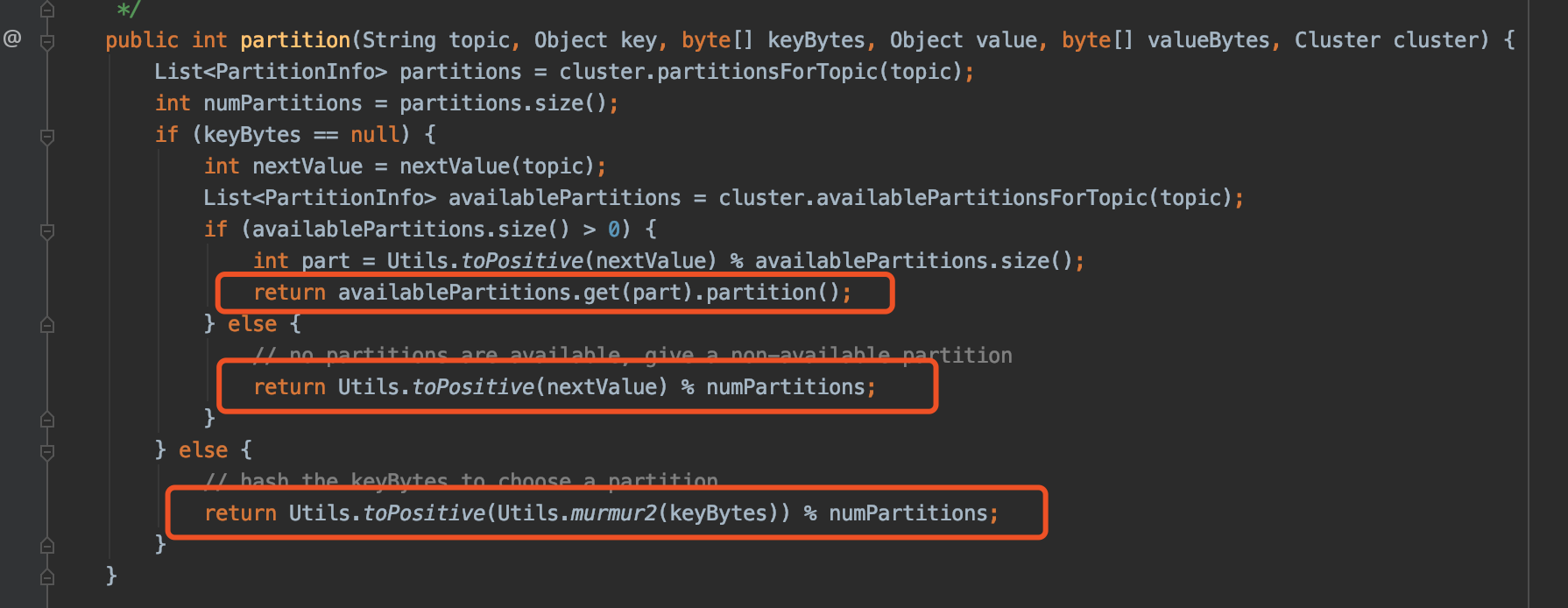
同一个Topic,每一个partition各自处理各自的消息。

每一个segment包含:日志(用来存储消息数据)和索引(用来记录offset相关映射信息)
通过分段,可以减少文件的大小以及通过稀疏索引进一步实现数据的快速查找。
可以通过配置log.dirs的值来修改数据存储的位置,默认是在/tmp/kafka-logs目录下。
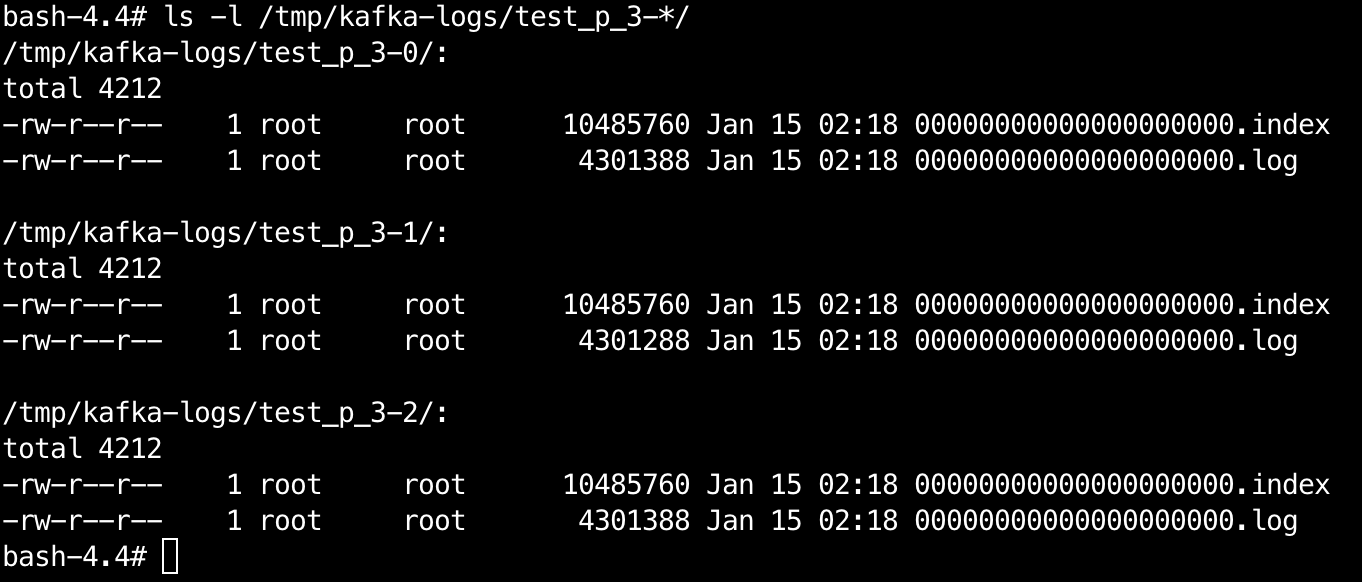
以相同基准offset命名的日志、索引文件,称为段。如果一个partition只有一个数据文件的话:
对于写入
由于是顺序追加写入,时间复杂度为O(1)对于查找
要查找某个offset,采用的是顺序查找,时间复杂度达到了O(n)
通过对数据进行分段、加索引,解决了痛点。
在Kafka中,索引文件分为:
| name | type | suffix |
|---|---|---|
| 偏移量索引 | OffsetIndex | .index |
| 时间戳索引 | TimeIndex | .timeindex |
| 事务索引 | TransactionIndex | .txnindex |
日志文件分为:
| name | suffix | desc |
|---|---|---|
| 数据文件 | .log | 用于存储消息 |
| 交换文件 | .swap | 用于segment的恢复 |
| 延迟待删文件 | .deleted | 用于标识要删除的文件 |
| 快照文件 | .snapshot | 用于记录producer的事务信息 |
| 清理临时文件 | .cleaned | 用于标识正在删除的文件 |
分段
假设有100条消息,offset取值范围在:0 - 99,如果分为4个段,那么每一个段各存储25条消息,取值范围分别为:0 - 24、25 - 49、 50 - 74、75 - 99,而每一段的文件以20位起始offset来命名,不足20位,用0补齐,要查找某个offset只需要找到对应范围内的文件,然后再通过二分查找算法去文件查找即可。
1 | 通过kafka.tools.DumpLogSegments可以查看log文件的内容 |
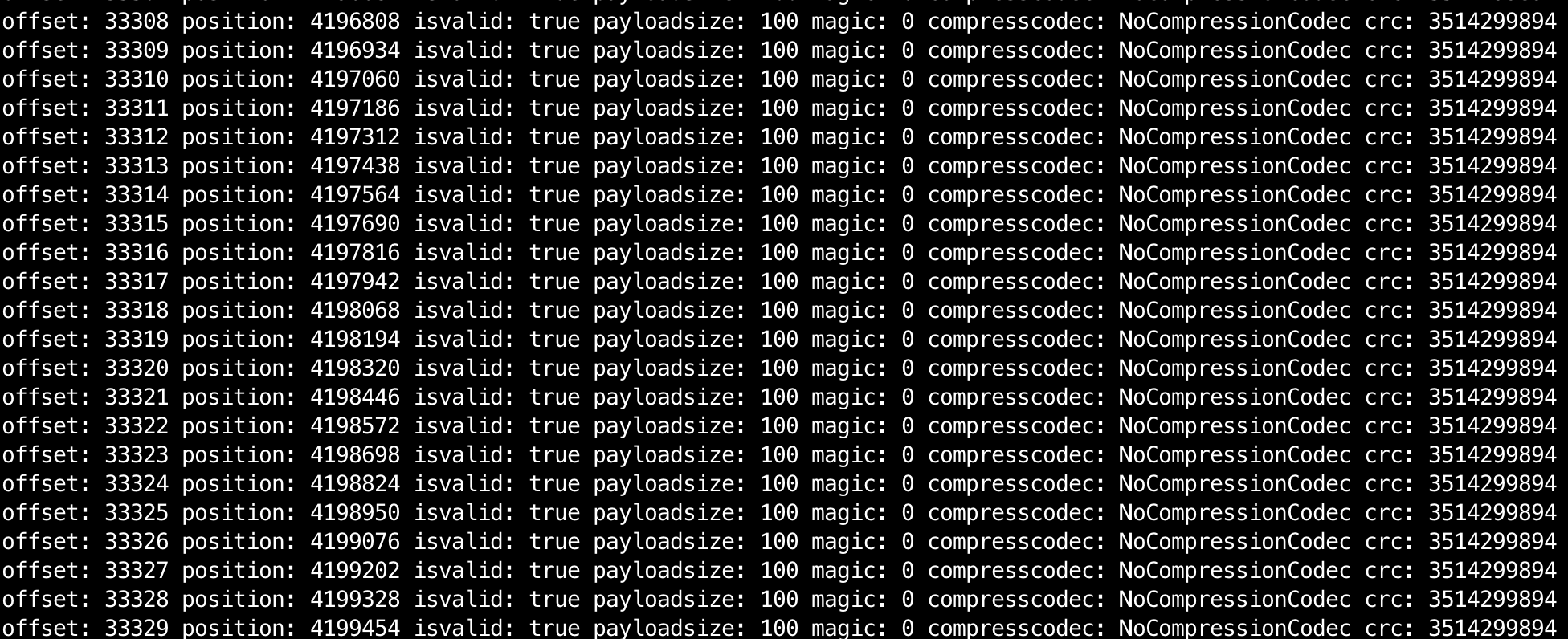
索引
通过分段可以减少数据文件大小,并且加快查询速度,但仍然存在顺序查找的最差情况。
为了进一步提高数据查找的速度,Kafka通过建立稀疏索引的方式,每隔一定间隔建立一条索引。
1 | 通过kafka.tools.DumpLogSegments可以查看index文件的内容 |
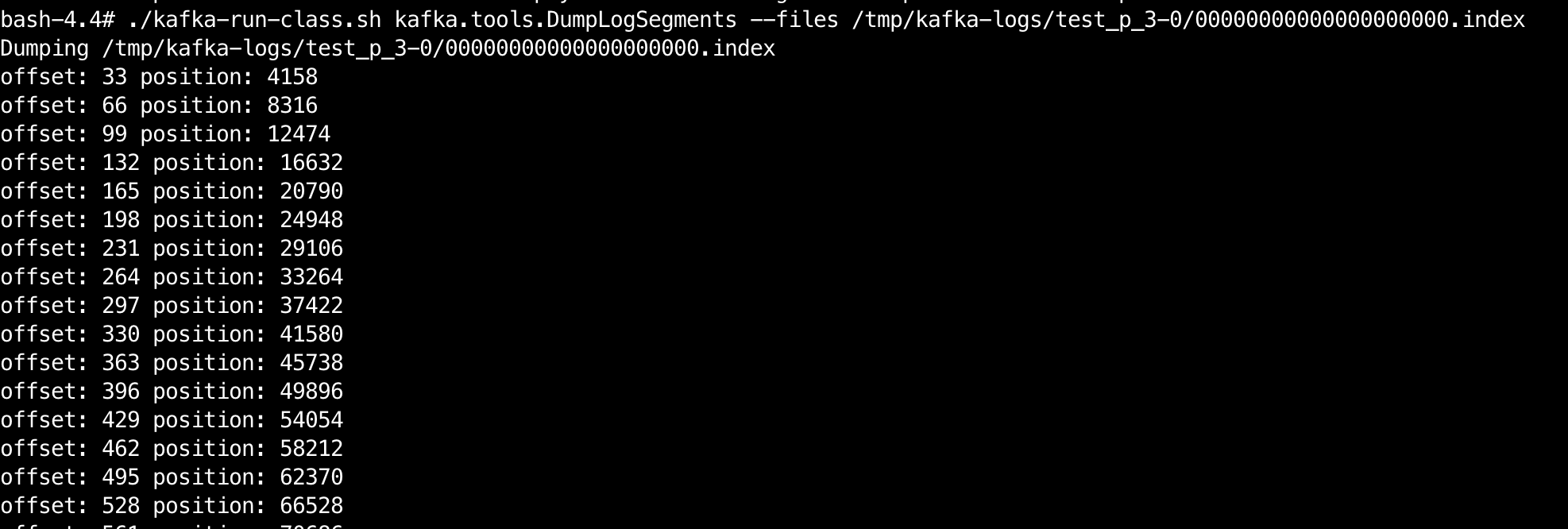
偏移量索引,记录着 < offset , position > 偏移量 - 物理地址
时间戳索引,记录着 < timestamp , offset >时间戳 - 偏移量
事务索引,记录着 < offset , AbortedTxn > 偏移量 - 被中断事务
消息查找:offset、timestamp在Kafka中,segment通过一个跳跃表来维护。
1 | /* the actual segments of the log */ |
每一次,只有一个activeSegment可以进行写入消息,其它的segment是只读的。
1 | /** |
基于偏移量查找
OffsetIndex的数据格式为:
1 | offset: 33 position 4158 |
在Kafka的IndexEntry.scala中定义为:
1 | /** |
如果要查找offset=35的消息,那么就先从segments跳跃表上找到对应应访问的segment文件。
然后通过二分查找在偏移量索引文件找到不大于35的offset,也就是offset: 33 position 4158。
解析offset对应的position,从position处顺序查找log文件,找到offset=35的位置。
基于时间戳查找
TimeIndex的数据格式为:
1 | timestamp: 1579167998000 offset 33 |
在Kafka的IndexEntry.scala中定义为:
1 | /** |
如果要查找timestamp=15791679981234的消息,那么就先比较每个segment文件的largestTimestamp,找到对应的segment文件。
然后通过二分查找在时间戳索引文件找到不大于15791679981234的timestamp,也就是timestamp: 1579167998000 offset 33。
找到offset直接去偏移量索引文件中查找position。
从position处顺序查找log文件,找到timestamp=15791679981234的位置。