/** * This callback is invoked by the zookeeper leader elector on electing the current broker as the new controller. * It does the following things on the become-controller state change - * 1. Registers controller epoch changed listener * 2. Increments the controller epoch * 3. Initializes the controller's context object that holds cache objects for current topics, live brokers and * leaders for all existing partitions. * 4. Starts the controller's channel manager * 5. Starts the replica state machine * 6. Starts the partition state machine * If it encounters any unexpected exception/error while becoming controller, it resigns as the current controller. * This ensures another controller election will be triggered and there will always be an actively serving controller */ privatedefonControllerFailover() { info("Reading controller epoch from ZooKeeper") //读取zk上/controller_epoch的值 readControllerEpochFromZooKeeper() info("Incrementing controller epoch in ZooKeeper") //将/controller_epoch的值 +1 incrementControllerEpoch() info("Registering handlers") //注册监听器,监听Topic、Broker、ISR等的变化 // before reading source of truth from zookeeper, register the listeners to get broker/topic callbacks val childChangeHandlers = Seq(brokerChangeHandler,topicChangeHandler, topicDeletionHandler,logDirEventNotificationHandler,isrChangeNotificationHandler) childChangeHandlers.foreach(zkClient.registerZNodeChildChangeHandler) val nodeChangeHandlers = Seq(preferredReplicaElectionHandler, partitionReassignmentHandler) nodeChangeHandlers.foreach(zkClient.registerZNodeChangeHandlerAndCheckExistence) //删除监听器,isr变更或者日志目录变更会触发监听器,进行重分配 info("Deleting log dir event notifications") zkClient.deleteLogDirEventNotifications() info("Deleting isr change notifications") zkClient.deleteIsrChangeNotifications() info("Initializing controller context") //初始化控制器上下文 initializeControllerContext() info("Fetching topic deletions in progress") val (topicsToBeDeleted, topicsIneligibleForDeletion) = fetchTopicDeletionsInProgress() info("Initializing topic deletion manager") //初始化Topic管理器 topicDeletionManager.init(topicsToBeDeleted, topicsIneligibleForDeletion)
// We need to send UpdateMetadataRequest after the controller context is initialized and before the state machines // are started. The is because brokers need to receive the list of live brokers from UpdateMetadataRequest before // they can process the LeaderAndIsrRequests that are generated by replicaStateMachine.startup() and // partitionStateMachine.startup(). info("Sending update metadata request") sendUpdateMetadataRequest(controllerContext.liveOrShuttingDownBrokerIds.toSeq)
info(s"Ready to serve as the new controller with epoch $epoch") //触发重新分配 maybeTriggerPartitionReassignment(controllerContext.partitionsBeingReassigned.keySet) //尝试删除无效Topic topicDeletionManager.tryTopicDeletion() val pendingPreferredReplicaElections = fetchPendingPreferredReplicaElections() //执行选举 onPreferredReplicaElection(pendingPreferredReplicaElections) info("Starting the controller scheduler") //启动kafka重分配定时任务 kafkaScheduler.startup() if (config.autoLeaderRebalanceEnable) { scheduleAutoLeaderRebalanceTask(delay = 5, unit = TimeUnit.SECONDS) } //启动token认证定时任务 if (config.tokenAuthEnabled) { info("starting the token expiry check scheduler") tokenCleanScheduler.startup() tokenCleanScheduler.schedule(name = "delete-expired-tokens", fun = tokenManager.expireTokens, period = config.delegationTokenExpiryCheckIntervalMs, unit = TimeUnit.MILLISECONDS) } }
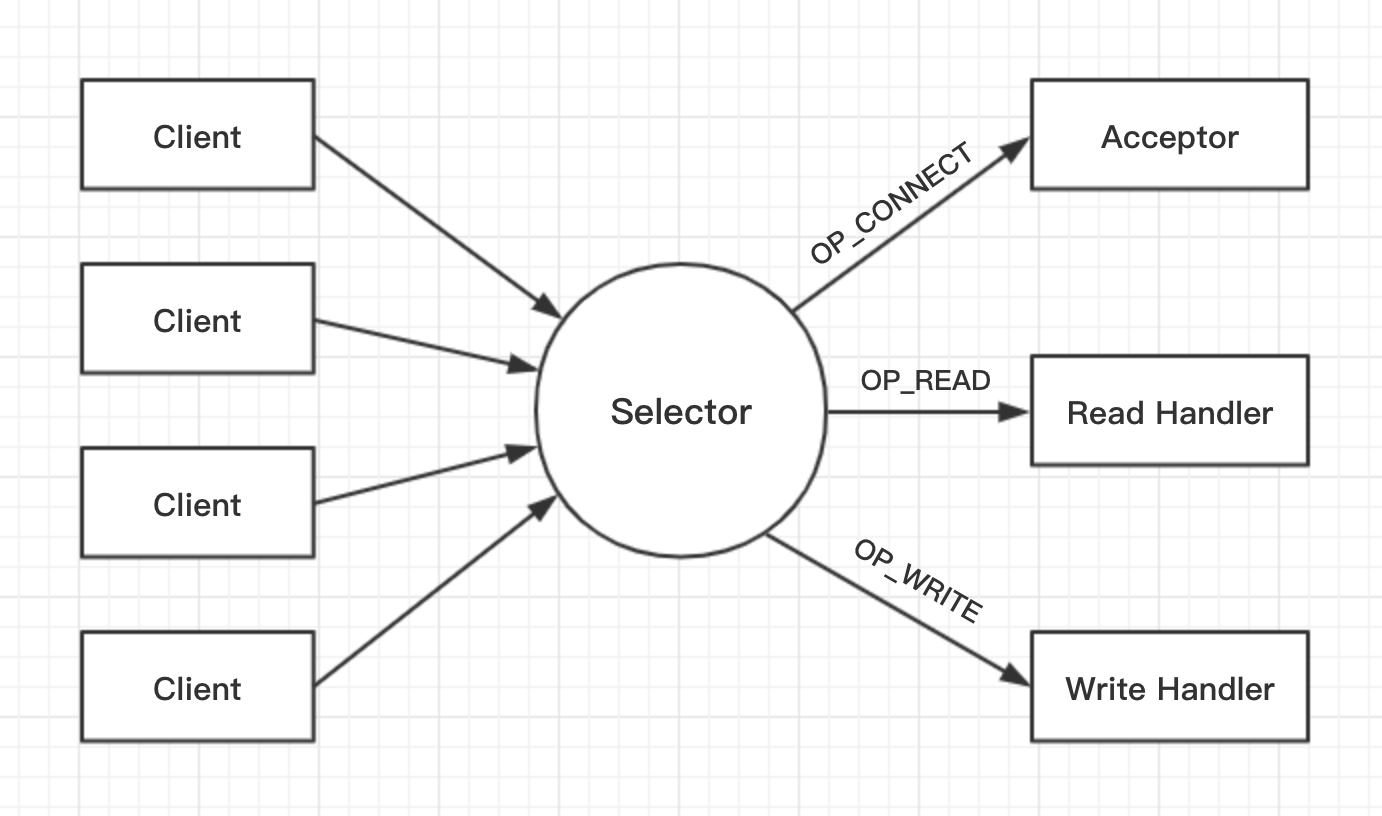
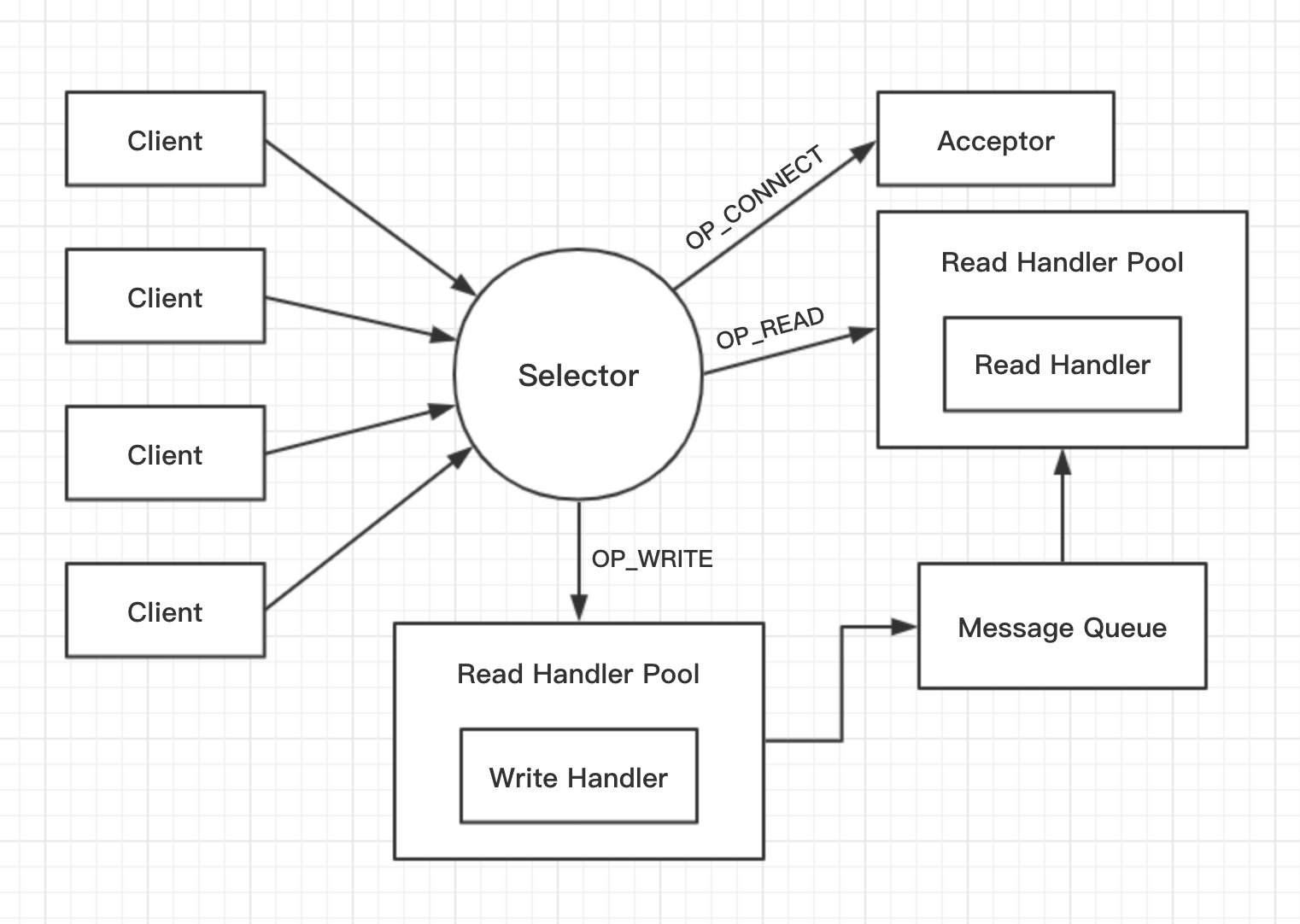
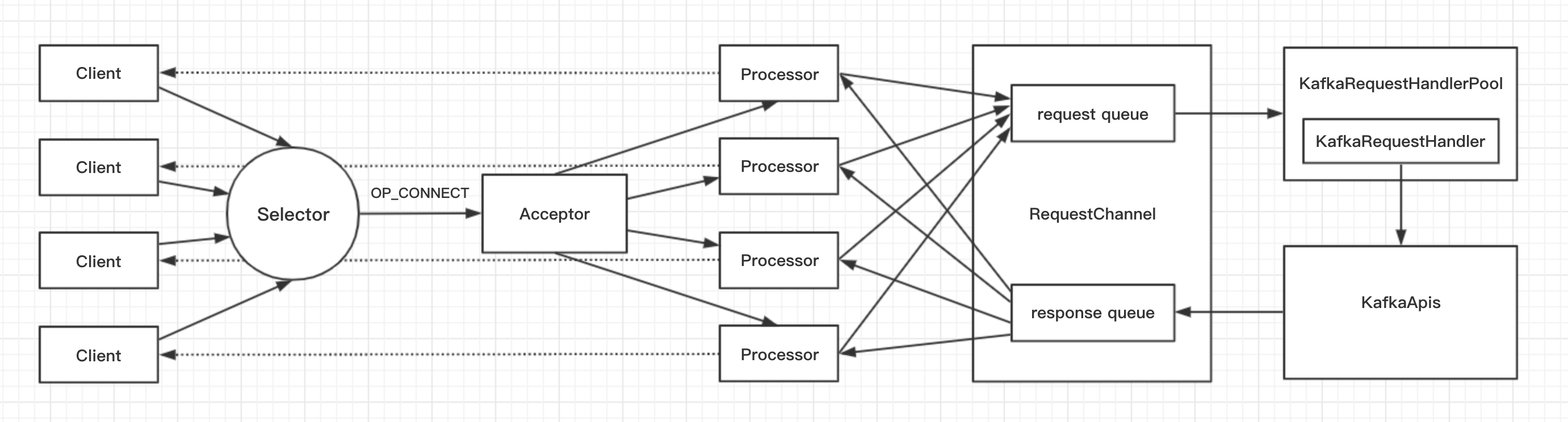
/** * An NIO socket server. The threading model is * 1 Acceptor thread that handles new connections * Acceptor has N Processor threads that each have their own selector and read requests from sockets * M Handler threads that handle requests and produce responses back to the processor threads for writing. */
// Create and start the socket server acceptor threads so that the bound port is known. // Delay starting processors until the end of the initialization sequence to ensure // that credentials have been loaded before processing authentications. //启动Acceptor,绑定端口 socketServer = newSocketServer(config, metrics, time, credentialProvider) socketServer.startup(startupProcessors = false)
/** * Accept loop that checks for new connection attempts */ defrun() { serverChannel.register(nioSelector, SelectionKey.OP_ACCEPT) startupComplete() try { var currentProcessor = 0 while (isRunning) { try { val ready = nioSelector.select(500) if (ready > 0) { val keys = nioSelector.selectedKeys() val iter = keys.iterator() while (iter.hasNext && isRunning) { try { val key = iter.next iter.remove() if (key.isAcceptable) { val processor = synchronized { currentProcessor = currentProcessor % processors.size processors(currentProcessor) } //获取连接 accept(key, processor) } else thrownewIllegalStateException("Unrecognized key state for acceptor thread.")
// 轮询到下一个Processor currentProcessor = currentProcessor + 1 } catch { case e: Throwable => error("Error while accepting connection", e) } } } } catch { // We catch all the throwables to prevent the acceptor thread from exiting on exceptions due // to a select operation on a specific channel or a bad request. We don't want // the broker to stop responding to requests from other clients in these scenarios. case e: ControlThrowable => throw e case e: Throwable => error("Error occurred", e) } } } finally { debug("Closing server socket and selector.") CoreUtils.swallow(serverChannel.close(), this, Level.ERROR) CoreUtils.swallow(nioSelector.close(), this, Level.ERROR) shutdownComplete() } }
overridedefrun() { startupComplete()//CountDownLatch try { while (isRunning) { try { //从队列中取出连接 configureNewConnections() //处理responseQueue processNewResponses() //selector.poll poll() //处理requestQueue processCompletedReceives() //移除inflightResponses processCompletedSends() //移除连接 processDisconnected() } catch { // We catch all the throwables here to prevent the processor thread from exiting. We do this because // letting a processor exit might cause a bigger impact on the broker. This behavior might need to be // reviewed if we see an exception that needs the entire broker to stop. Usually the exceptions thrown would // be either associated with a specific socket channel or a bad request. These exceptions are caught and // processed by the individual methods above which close the failing channel and continue processing other // channels. So this catch block should only ever see ControlThrowables. case e: Throwable => processException("Processor got uncaught exception.", e) } } } finally { debug("Closing selector - processor " + id) CoreUtils.swallow(closeAll(), this, Level.ERROR) shutdownComplete() } }
classKafkaRequestHandlerPool(val brokerId: Int, val requestChannel: RequestChannel, val apis: KafkaApis, time: Time, numThreads: Int) extendsLoggingwithKafkaMetricsGroup{ //线程池大小 privateval threadPoolSize: AtomicInteger = newAtomicInteger(numThreads) /* a meter to track the average free capacity of the request handlers */ privateval aggregateIdleMeter = newMeter("RequestHandlerAvgIdlePercent", "percent", TimeUnit.NANOSECONDS)
this.logIdent = "[Kafka Request Handler on Broker " + brokerId + "], " val runnables = new mutable.ArrayBuffer[KafkaRequestHandler](numThreads) for (i <- 0 until numThreads) { createHandler(i) } //启动KafkaRequestHandler线程 defcreateHandler(id: Int): Unit = synchronized { runnables += newKafkaRequestHandler(id, brokerId, aggregateIdleMeter, threadPoolSize, requestChannel, apis, time) KafkaThread.daemon("kafka-request-handler-" + id, runnables(id)).start() }
defresizeThreadPool(newSize: Int): Unit = synchronized { val currentSize = threadPoolSize.get info(s"Resizing request handler thread pool size from $currentSize to $newSize") if (newSize > currentSize) { for (i <- currentSize until newSize) { createHandler(i) } } elseif (newSize < currentSize) { for (i <- 1 to (currentSize - newSize)) { runnables.remove(currentSize - i).stop() } } threadPoolSize.set(newSize) }
defshutdown(): Unit = synchronized { info("shutting down") for (handler <- runnables) handler.initiateShutdown() for (handler <- runnables) handler.awaitShutdown() info("shut down completely") } }
/** * A thread that answers kafka requests. */ classKafkaRequestHandler(id: Int, brokerId: Int, val aggregateIdleMeter: Meter, val totalHandlerThreads: AtomicInteger, val requestChannel: RequestChannel, apis: KafkaApis, time: Time) extendsRunnablewithLogging{ this.logIdent = "[Kafka Request Handler " + id + " on Broker " + brokerId + "], " privateval shutdownComplete = newCountDownLatch(1) @volatileprivatevar stopped = false
defrun() { while (!stopped) { // We use a single meter for aggregate idle percentage for the thread pool. // Since meter is calculated as total_recorded_value / time_window and // time_window is independent of the number of threads, each recorded idle // time should be discounted by # threads. val startSelectTime = time.nanoseconds //获取请求 val req = requestChannel.receiveRequest(300) val endTime = time.nanoseconds val idleTime = endTime - startSelectTime aggregateIdleMeter.mark(idleTime / totalHandlerThreads.get) req match { caseRequestChannel.ShutdownRequest => debug(s"Kafka request handler $id on broker $brokerId received shut down command") shutdownComplete.countDown() return
case request: RequestChannel.Request => try { request.requestDequeueTimeNanos = endTime trace(s"Kafka request handler $id on broker $brokerId handling request $request") //由KafkaApis来处理业务逻辑 apis.handle(request) } catch { case e: FatalExitError => shutdownComplete.countDown() Exit.exit(e.statusCode) case e: Throwable => error("Exception when handling request", e) } finally { request.releaseBuffer() }
privatedefsendResponse(request: RequestChannel.Request, responseOpt: Option[AbstractResponse]): Unit = { // Update error metrics for each error code in the response including Errors.NONE responseOpt.foreach(response => requestChannel.updateErrorMetrics(request.header.apiKey, response.errorCounts.asScala))
responseOpt match { caseSome(response) => val responseSend = request.context.buildResponse(response) val responseString = if (RequestChannel.isRequestLoggingEnabled) Some(response.toString(request.context.apiVersion)) elseNone requestChannel.sendResponse(newRequestChannel.Response(request, Some(responseSend), SendAction, responseString)) caseNone => requestChannel.sendResponse(newRequestChannel.Response(request, None, NoOpAction, None)) } }
/** Send a response back to the socket server to be sent over the network */ defsendResponse(response: RequestChannel.Response) { if (isTraceEnabled) { val requestHeader = response.request.header val message = response.responseAction match { caseSendAction => s"Sending ${requestHeader.apiKey} response to client ${requestHeader.clientId} of ${response.responseSend.get.size} bytes." caseNoOpAction => s"Not sending ${requestHeader.apiKey} response to client ${requestHeader.clientId} as it's not required." caseCloseConnectionAction => s"Closing connection for client ${requestHeader.clientId} due to error during ${requestHeader.apiKey}." } trace(message) }
val processor = processors.get(response.processor) // The processor may be null if it was shutdown. In this case, the connections // are closed, so the response is dropped. if (processor != null) { processor.enqueueResponse(response) } }
1 2 3 4
private[network] defenqueueResponse(response: RequestChannel.Response): Unit = { responseQueue.put(response) wakeup() }