Kafka的高性能在于设计巧妙及借助操作系统特性。Kafka消息的生产和消费都是需要指定Topic的。
首先,从表面设计方面来看。
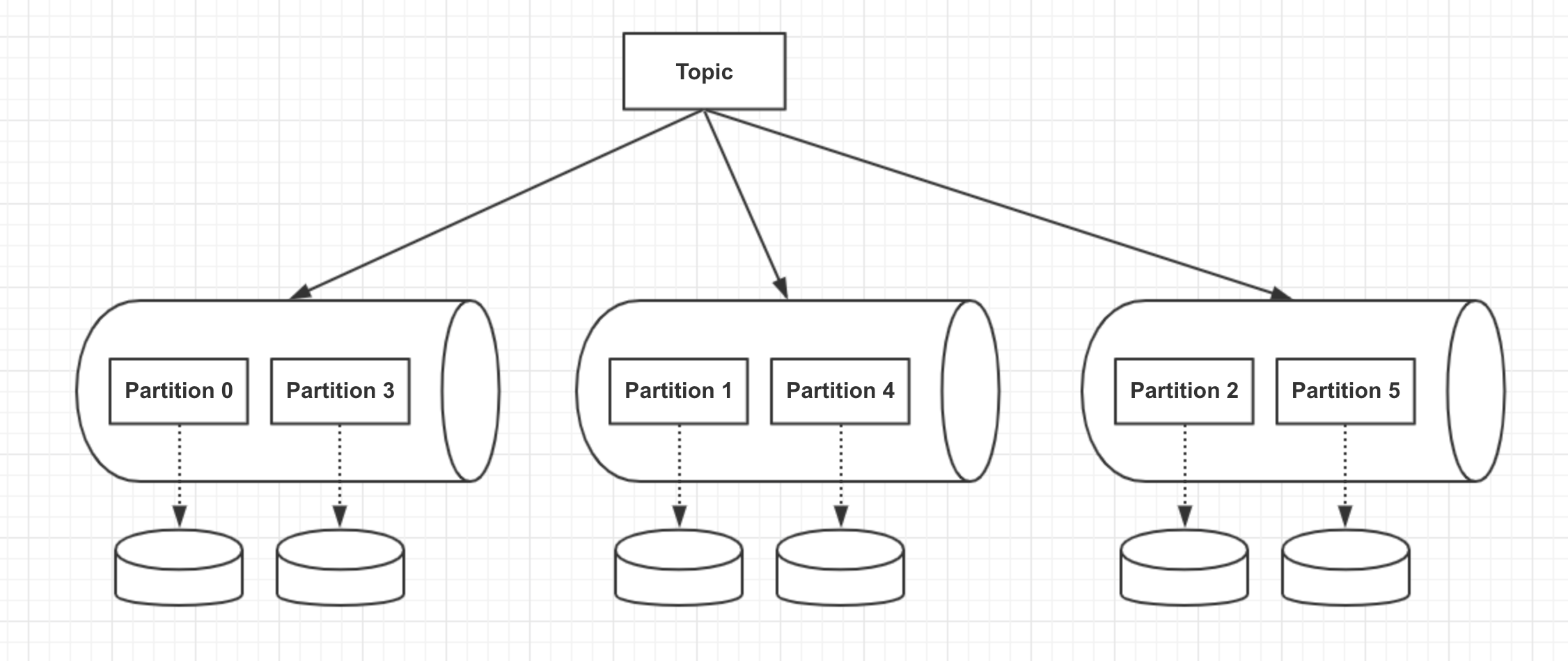
一个Topic可以拆分为多个Partition,而这些Partition可以均匀部署在多个Broker上,充分发挥集群的作用,实现机器并行处理。每个Partition再分为多个Segment,每次只有一个Segment可以进行日志的顺序写入,其它Segment可以根据offset进行读取。
对于日志的存储路径,Kafka支持多磁盘路径,通过配置log.dirs,按逗号分隔,可以实现磁盘并行处理。
接着,从底层实现方面来看。
Kafka采用了顺序写的方式,对于一些场景,顺序写磁盘比随机写内存来得快。
另外,由于Segment的存在,使得Kafka删除旧数据的时候更简单,直接删除老的Segment文件,而不需要操作一个文件去删除内容,也避免了随机写的操作。
Kafka充分利用了Page Cache,如果读写速率相当,只需要操作Page Cache即可,而不需要操作磁盘,数据会由I/O调度器定时组装成大块刷入磁盘中。
通过Page Cache的方式,Kafka不需要使用JVM的堆内存,也减少了GC的负担。
数据通过网络传输然后持久化到磁盘中,也从磁盘传输到网络中,Kafka采用了NIO零拷贝机制,减少了内核空间、用户空间的数据拷贝过程以及上下文切换次数。
Kafka从Producer到Broker发送的数据并没有直接发送过去,而是先缓存起来,积累一定条数或者等待一定时间,然后合并、压缩、序列化,批量发送到Broker,降低了网络负载,提高了传输效率。