Kafka的背景kafka是一个分布式、高性能、高可用、可水平拓展的发布-订阅式消息队列,更是一个流式处理系统。
对于消息,提供了O(1)时间复杂度的持久化能力,具备高吞吐率,同时支持实时、离线数据处理。
Kafka的架构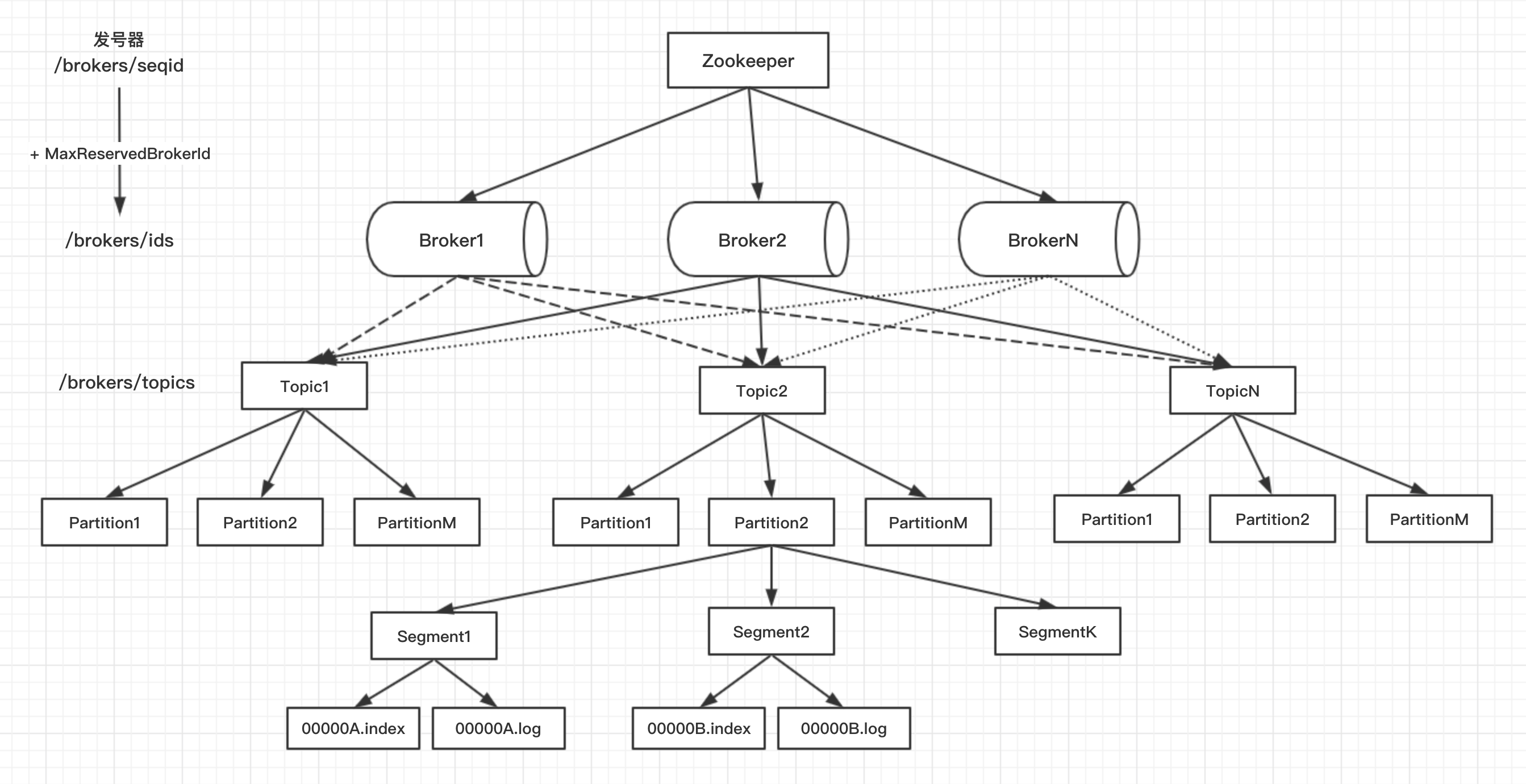 Kafka包含了:
Kafka包含了:
Broker: Kafka运行所在的服务器。Topic: Kafka生产、消费数据都是需要指定一个Topic的,相当于一个队列。Partition: 一个Topic可划分多个Partition,多机部署,可定义partition路由算法。Segment: 一个Partition被切分为多个Segment,每个Segment包含索引文件和数据文件。Producer: 生产者只需要指定Topic,往里头写数据即可。Consumer: 一个Consumer Group包含多个Consumer,一条消息只被同组中的一个消费。Zookeeper: Zookeeper用来管理Kafka集群。
对于服务器来说,Broker只是一个进程。
Topic则是服务器上的目录,存放在log.dirs指定的路径下,默认是/tmp/kafka-logs,支持多路径,逗号分隔,可将数据分散到多个磁盘中,使Kafka吞吐率线性提高。通过指定--partitions数值,可创建多个Partition,命名为TopicName-K,从0开始。
通过指定--replication-factor副本因子数值,可将这些Partition分散、备份在一个或多个可用的Broker中,前提是可用的Broker数要大于等于replication-factor的值,既可数据备份、又可实现高可用、分散负载,提高吞吐量。
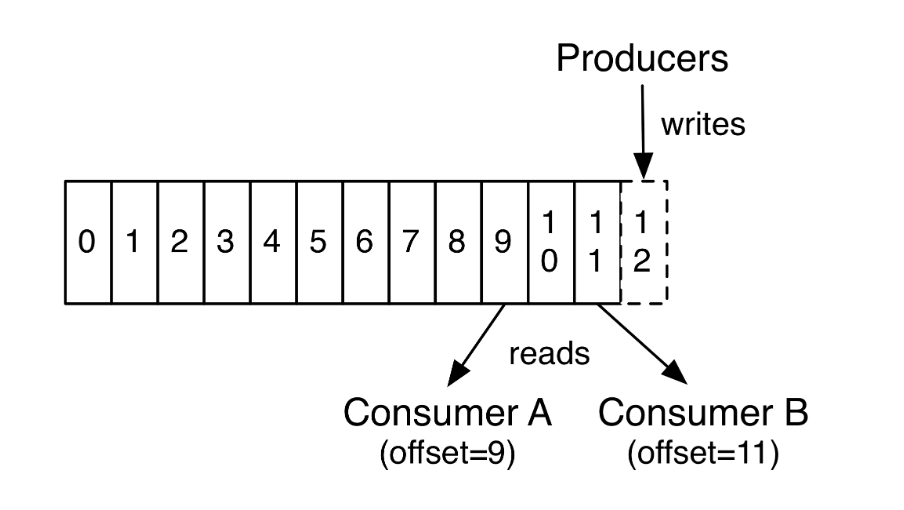
每个Partiton目录下存储的是一段段的Segment,包含了索引文件和数据文件,以offset命名。
Kafka采用推拉结合模型在生产消息方面,采用主动推送消息模式,在客户端会累积、压缩、批量发送到Broker。
在消费消息方面,采用主动拉取消息模式,由客户端轮询拉取消息,并按照策略提交offset。
另外,通过消费者拉消息的方式,可以由消费者自行控制消费的频率。
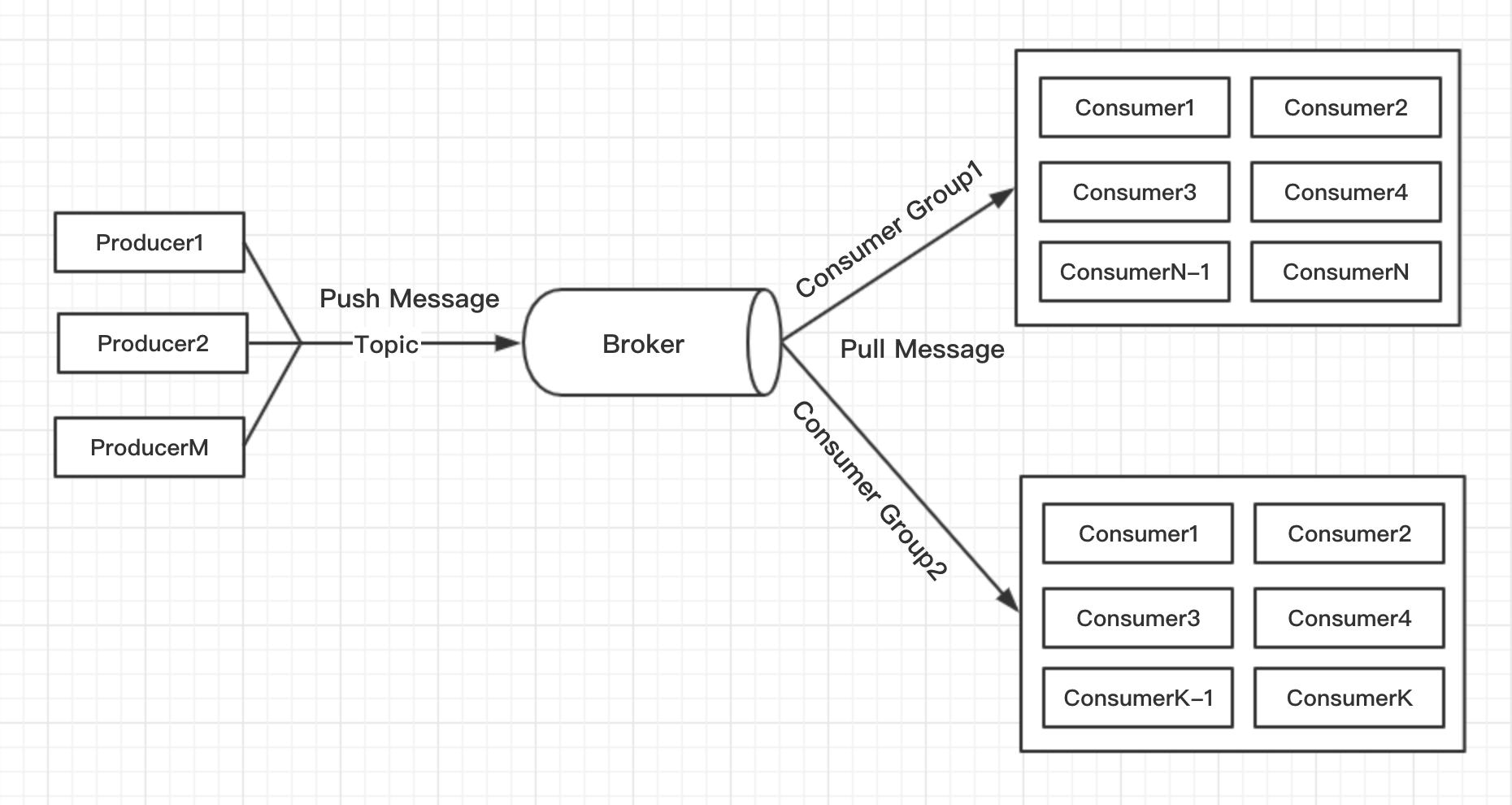
此种方式,有利于减轻Broker压力,不需要维护太多状态,可由客户端自定义从哪个offset开始拉取消息。